
LeetCodeって?

LeetCodeとは、アルゴリズムやデータ構造を実践を通して学べる海外のプログラミング学習サイトです。
2022年12月現在2,000問を超える問題が登録されています。
各問題では、特定の入力をしたときに特定の返り値を出力する関数を作成することを求められます。
正誤判定は自動で行われます。
使用できる言語は、C++、C#、JAVA、Python3、Go、JSなど19言語が用意されています。
私はPython3で解いています。
問題

タイトル:3. Longest Substring Without Repeating Characters
難易度:Medium
内容:
与えられた文字列sの中から、同じ文字を2度使用しない最長の部分文字列の長さを返す。
例:
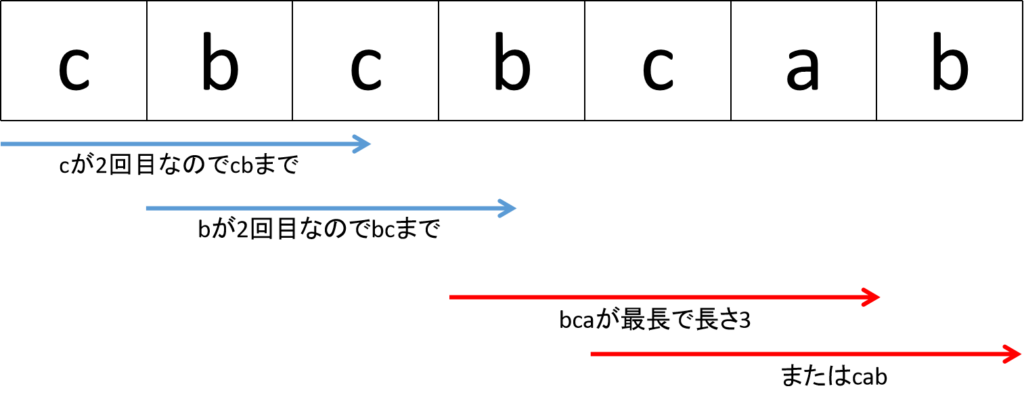
s = “cbcbcab”
output = 3
“cbcbcab”のなかで同じ文字を2度使用しない最長の部分文字列は、下図の通り”bca”または”cab”であり長さは3となります。
回答
今回は、効率を考えずに実装した場合と、効率を重視して実装した場合の処理速度の違いを見てみます。
効率を考慮しない場合
i文字目を起点に1文字ずつ文字を見ていき、これまで出てきた文字があった場合はそれまでの長さを記録しi+1文字目に移動する、を繰り返すやり方です。
下図の場合、1文字目の”c”を起点に、c→b→cでcが2度目なので長さ2を記録、
次に2文字目がb→c→bで2を記録、を繰り返していきます。
計算量は二重ループになるのでO(N2)です。

# 全文
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
max_len = 0
for i in range(len(s)):
tmp_length = 0
dic = {}
for j in range(len(s) - i):
if s[j + i] not in dic:
dic[s[j + i]] = 0
tmp_length += 1
else:
break
max_len = max(max_len, tmp_length)
return max_len結果
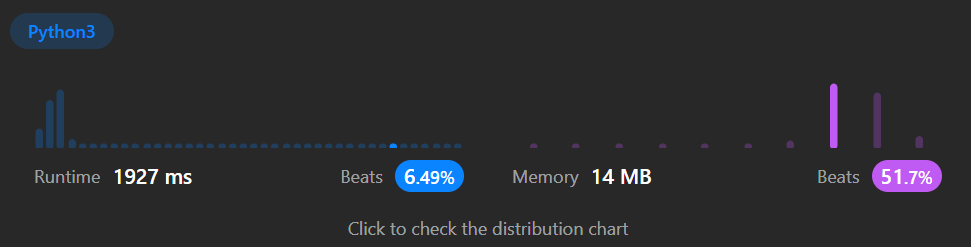
分かってはいましたがかなり遅いです。というか同じような解き方をしている人がほとんどいないみたいですね。LeetCodeのレベルの高さにビビります。。
これまで見つかった最大の文字列長さに応じて、後ろ側の処理をやめることもできますが焼け石に水でしょうね。
効率を重視する場合
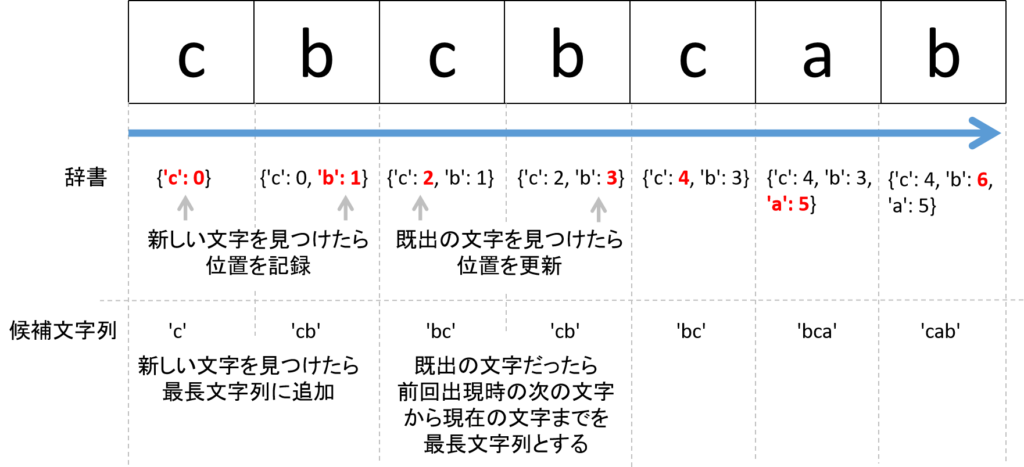
文字列を最初から見ていき、文字とその出現場所を辞書に記録していきます。
新しい文字が見つかる限り候補文字列に保管していきます。
すでに辞書に入っている文字が出てきた場合同じ文字が2つ入ってしまうので、前回出現した位置の次の文字から現在の文字までを候補文字列とします。
候補文字列のうち最も長いものの長さが返り値となります。
文字列を一度なぞるだけなので、計算量はO(N)です。
コード
# 全文
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
dic = {} # 辞書
left = -1 # 候補文字列左側位置
ans = 0 # 最長文字列長さ
# 文字列数分ループ
for i, l in enumerate(s):
# 現在の文字が辞書にありかつ、現在の候補文字列の左端より右側にあれば
if l in dic and dic[l] > left:
# 候補文字列の左側を更新
left = dic[l]
# 現在の文字の位置を辞書に追加
dic[l] = i
# 最長文字列長さ
ans = max(ans, i - left)
return ansコードはgithubにも保管しています。
結果
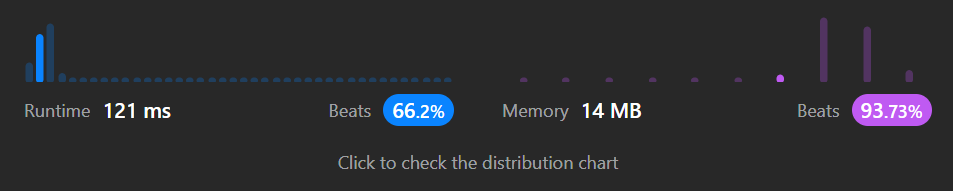
効率を考慮せずに作った場合に比べて処理速度が大幅に向上しました。


コメント