
日本中の気温の推移を数十年単位で可視化してみたく、気象庁が公開している全ての観測地点の過去の気象データをスクレイピングしました。
以下のサイトを参考にしています。
気象庁の過去データについて
気象庁の過去データ提供サービスは2種類あります。
本記事では2.過去の気象データ検索サービスの1日ごとのデータをスクレイピングします。
過去の気象データ・ダウンロードサービス

こちらのサービスを使うと、特定の場所、特定の期間、特定の気象情報(気温、降水量、風速など)をcsv形式でダウンロードすることができます。
しかし一度にダウンロードできるデータ容量が限られているため、全観測地点のデータを長期間にわたって取得しようとすると、大変な回数ダウンロードしなければならず現実的ではありません。
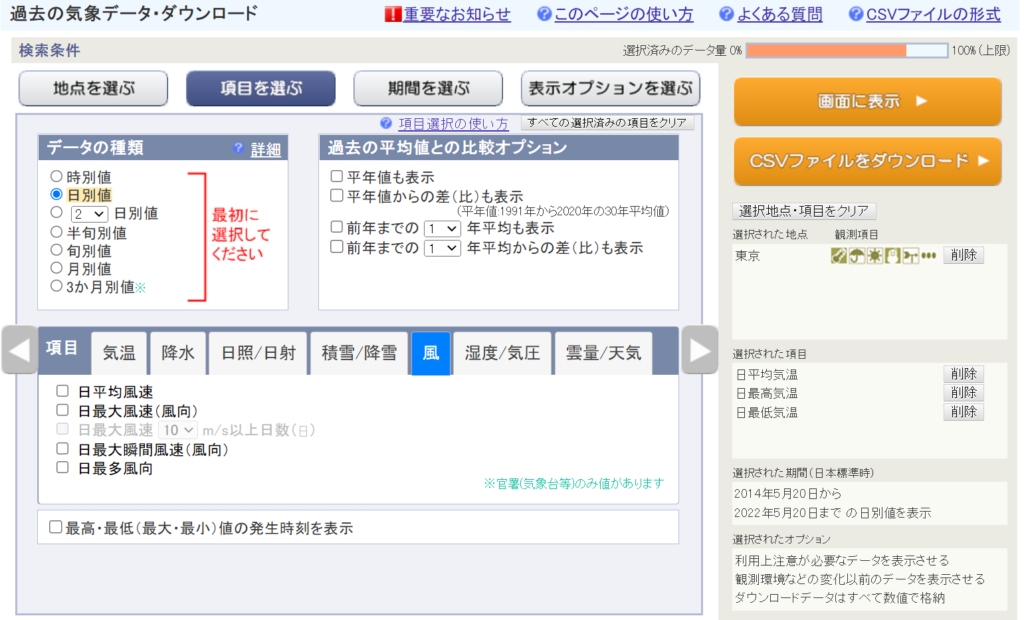
過去の気象データ検索サービス

こちらは、観測所、年月日を選択すると文字情報で気象情報を表示してくれるサイトです。10分毎、1時間ごと、1日ごとなど粒度別で取得が可能です。

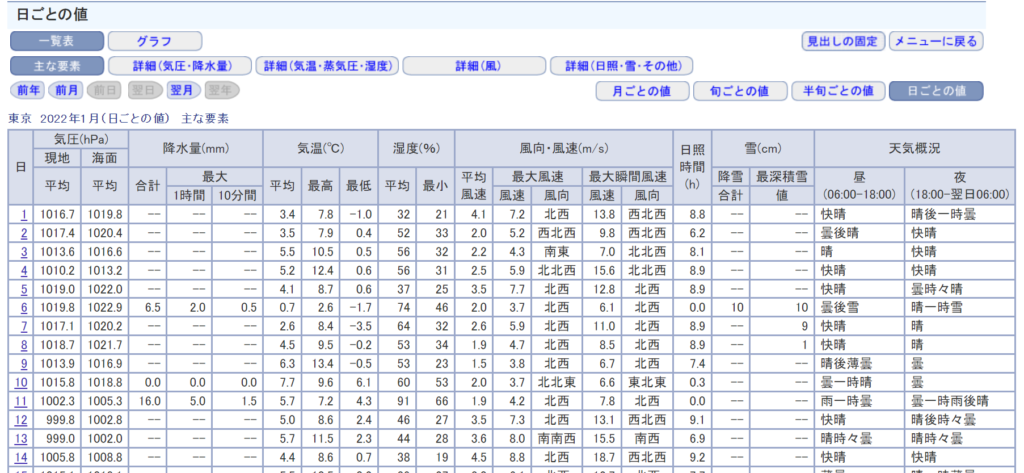
日ごとの値から、降水量の合計、平均気温・最高気温・最低気温、平均風速、降雪量の合計と最深積雪をスクレイピングで取得してみます。
準備
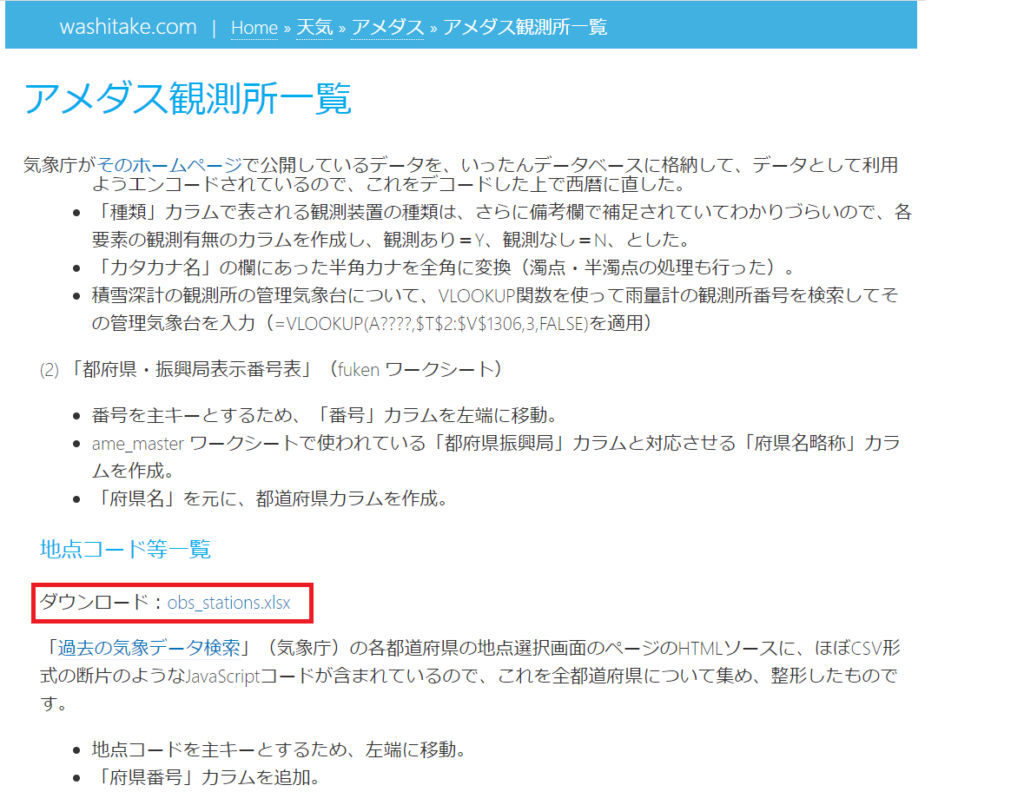
地点コード一覧の取得
全観測地点のデータを取得するので、そのコード一覧が必要になります。
こちらのページに、観測地点のコードをまとめたobs_stations.xlsxというエクセルファイルがあるので、これをダウンロードしてください。

ライブラリ
使用したライブラリは以下の通りです。必要に応じてインストールしてください。
- pandas
- datetime
- dateutil.relativedelta
- urllib.request
- BeautifulSoup
実装
環境は以下を使用しました。
- Windows11
- Python3.9.15
- Jupyter notebook6.5.2
コード
Jupyter notebook の形式で git にも保管しています。
パッケージのインポート
import pandas as pd
import datetime
from dateutil.relativedelta import relativedelta
import urllib.request
from bs4 import BeautifulSoup
観測地点一覧ファイルの読み込み。
一覧には観測を停止している地点も入っているので、観測を継続している地点のみを抽出します。また気温の観測を行っている地点に絞ります。
obs_stations = pd.read_excel("obs_stations.xlsx")
obs_stations = obs_stations.query('ed_y == 9999')
obs_stations = obs_stations.query('気温 == "Y"')データ取得開始と終了年月日の設定。
好きな年月日を設定して下さい。
長くしすぎるとデータの取得に数日単位でかかってしまうので注意してください。
start_date = datetime.date(2020, 1, 1)
end_date = datetime.date(2020, 12, 31)
メイン部分
Temp_data = pd.DataFrame(index=[], columns=['降水量','降雪量','積雪量','平均気温','最高気温','最低気温','平均風速'])
date = start_date
while date < end_date:
Temp_data.loc2025/11/30 = -100.0
date += relativedelta(days=1)
def str2float(weather_data):
try:
return float(weather_data)
except:
return -100
for i in obs_stations.index:
Temp_data_s = Temp_data.copy()
url_y = "https://www.data.jma.go.jp/obd/stats/etrn/view/annually_%s.php?" \
"prec_no=%d&block_no=%04d&year=&month=&day=&view=" \
%(str.lower(obs_stations['区分'].loc[i]), obs_stations['府県番号'].loc[i], obs_stations['地点コード'].loc[i])
html = urllib.request.urlopen(url_y).read()
soup = BeautifulSoup(html)
trs = soup.find("table", { "class" : "data2_s" })
if trs is None:
continue
tr = trs.findAll('tr')[3]
tds = tr.findAll('td')[0].findAll('div')[0].findAll('a')
date = start_date
# date = datetime.date(max(int(tds[0].string),1872), 1, 1)
while date < end_date:
url_m = "https://www.data.jma.go.jp/obd/stats/etrn/view/daily_%s1.php?" \
"prec_no=%s&block_no=%04d&year=%d&month=%d&day=&view=" \
%(str.lower(obs_stations['区分'].loc[i]), obs_stations['府県番号'].loc[i], obs_stations['地点コード'].loc[i], date.year, date.month)
html = urllib.request.urlopen(url_m).read()
soup = BeautifulSoup(html)
trs = soup.find("table", { "class" : "data2_s" })
if trs is None:
print(f"\r{obs_stations['地点'].loc[i]}", end="")
date += relativedelta(months=1)
continue
# table の中身を取得
date_day = date
print(f"\r{i,obs_stations['地点'].loc[i], obs_stations['地点コード'].loc[i], date_day.year, date_day.month}", end="")
if obs_stations['区分'].loc[i] == 'S':
for tr in trs.findAll('tr')[4:]:
tds = tr.findAll('td')
if tds[6].string == None or tds[7].string == None or tds[8].string == None:
break
Temp_data_s['降水量'].loc[date_day] = str2float((tds[3].string).split(' ')[0])
Temp_data_s['平均気温'].loc[date_day] = str2float((tds[6].string).split(' ')[0])
Temp_data_s['最高気温'].loc[date_day] = str2float((tds[7].string).split(' ')[0])
Temp_data_s['最低気温'].loc[date_day] = str2float((tds[8].string).split(' ')[0])
Temp_data_s['降雪量'].loc[date_day] = str2float((tds[17].string).split(' ')[0])
Temp_data_s['積雪量'].loc[date_day] = str2float((tds[18].string).split(' ')[0])
Temp_data_s['平均風速'].loc[date_day] = str2float((tds[11].string).split(' ')[0])
date_day += relativedelta(days=1)
else:
for tr in trs.findAll('tr')[3:]:
tds = tr.findAll('td')
if tds[4].string == None or tds[5].string == None or tds[6].string == None:
break
Temp_data_s['降水量'].loc[date_day] = str2float((tds[1].string).split(' ')[0])
Temp_data_s['平均気温'].loc[date_day] = str2float((tds[4].string).split(' ')[0])
Temp_data_s['最高気温'].loc[date_day] = str2float((tds[5].string).split(' ')[0])
Temp_data_s['最低気温'].loc[date_day] = str2float((tds[6].string).split(' ')[0])
Temp_data_s['降雪量'].loc[date_day] = str2float((tds[16].string).split(' ')[0])
Temp_data_s['積雪量'].loc[date_day] = str2float((tds[17].string).split(' ')[0])
Temp_data_s['平均風速'].loc[date_day] = str2float((tds[9].string).split(' ')[0])
date_day += relativedelta(days=1)
date += relativedelta(months=1)
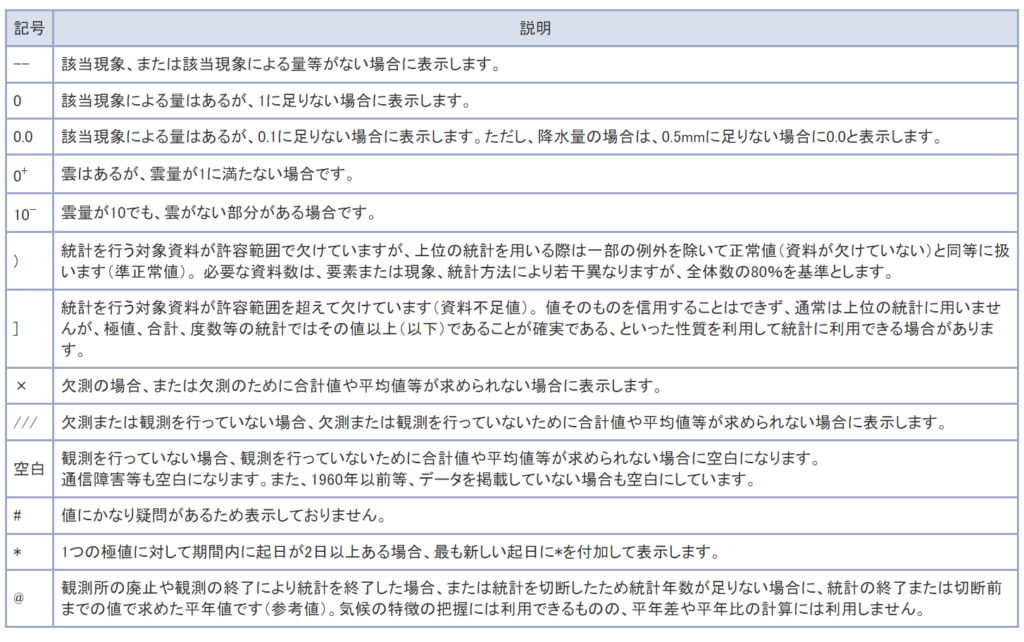
Temp_data_s.to_csv("%d_%s.csv"%(obs_stations['地点コード'].loc[i],obs_stations['地点'].loc[i]))なお上記のコードでは、欠測や降水がない場合などで数値が入っていないところを一律 -100 にしています。
実際には以下の記号が入っているので区別したい場合はカスタマイズしてください。
結果
各観測地点の気象データがそれぞれのファイルで保存されました。
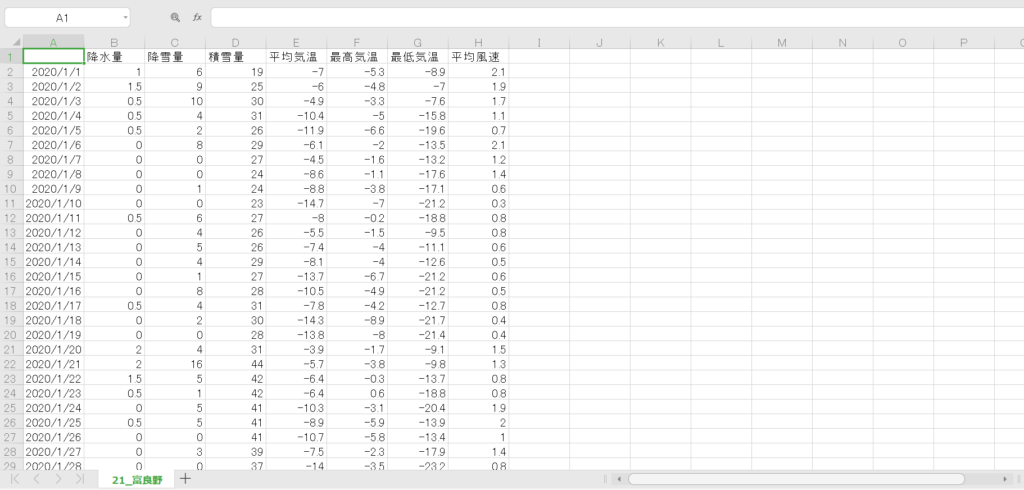
中身はこんな感じです。ちゃんと値を取得できていますね。
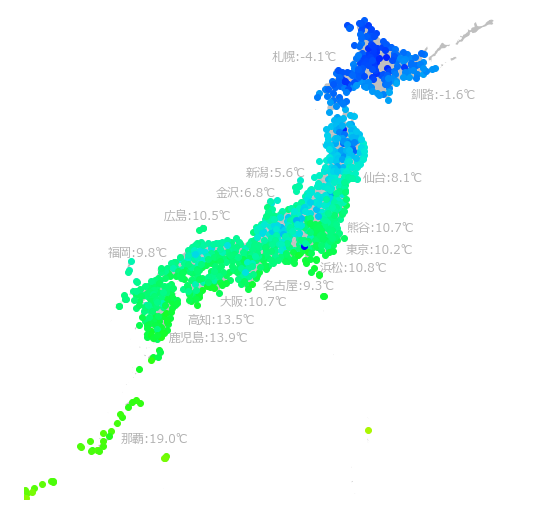
試しに 2020/1/1 の最高気温を地図上にプロットしてみました。
各観測地点の緯度経度は準備でダウンロードした obs_stations.xlsx に記載されています。
まとめ
今回は、Python を使って、気象庁の過去の気象データ検索サービスから、特定期間の全ての観測地点の気象データをスクレイピングする方法について記載しました。
次回は、取得したデータを地図上にプロットし、長期的な変化を可視化する方法について記載しようと思います。
本日は以上です。ご覧いただきありがとうございました!

コメント